Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
Last Updated: May 07 2025.
Published:
Last Updated: August 27 2023.
Published:
Last Updated: December 08 2025.
Published:
Last Updated: August 26 2024.
Published:
Last Updated: January 31 2023.
Published:
Thank you for being interested in working with me. I enjoy working with students. And yes, I am looking for PhD students starting from Fall 2023 (application due by December 15, 2022). Feel free to send your CV and your transcript to hungle@cs.umass.edu. Check out here for general requirement; GRE is NOT required for PhD admission. Having a good math background will be appreciated. Note that I cannot answer questions regarding your chance of being admitted. This year, our college, Manning CICS, provides support for Iranian PhD Applicants.
Published:
Last Updated: August 14 2022.
Published:
Objectives: This course provides students with skills in designing efficient algorithms. After completing this course, students are expected to be able to formulate an algorithmic problem, design an algorithm for the problem, prove the correctness, and analyze the running time. This course will illustrate these skills through various algorithmic problems and important design techniques.
Published:
Course website on Heat for SENG 474 and CSC 578D. There will be no further update on these two sites. More up-to-date contents will be on this site.
Published:
Due by March 25, 2019 11:55 pm
Goal: In this assignment, we learn how to factorize the utility matrix to build recommender systems. We will use the MovieLens 100k Dataset. This dataset contains about 100k ratings from n = 943 users and m = 1682 movies. We will factorize the utility matrix into two matrices U, V of dimensions nxd and dxm, respectively, where d = 20.
Input File: Dowload file ml-100k.zip, look for the file name u.data. We only use data in this file to do factorization. DO NOT assume that users and movies are indexed from 0 to n and m, respectively.
Input Format: Each row has four tab-separated columns of the form:
which means that user 196 gave a rating of 3 to movie 242 at timestamp 881250949. For the matrix factorization approach, we will ignore the timestamp feature. It may be helpful to look at the toy dataset.
Output Format: Two files, named UT.tsv and VT.tsv, correspond to two matrices U and V:
See UT.tsv and VT.tsv for sample outputs of the toy dataset with d = 2.
There is only one question worth 50 points.
Question (50 points): Factorize the utility matrix into two matrix U and V. You should run your algorithm with T = 20 iterations. For full score, your algorithm must run in less than 5 minutes with RMSE less than 0.62.
Note 1: Submit your code and output data to the Connex
Q1: How do I initialize matrices U and V?
Answer: I initialize entries of U and V by randomly selecting numbers from [0,1] using numpy.random.random_sample().
Published:
Due by March 04, 2019 11:55 pm
Please note that written homework 3 is up.
Goal: In this assignment, we will compute PageRank score for the web dataset provided by Google in a programming challenge in a programming constest in 2002.
Input Format: The datasets are given in txt. The file format is:
There are two dataset that we will work with in this assignment.
Also, it’s helpful to test your algorithm with this toy dataset.
Output Format: the output format for each quesion will be specified below.
There are two questions in this assigment worth 50 points total.
Question 1 (20 points): Find all dead ends. A node is a dead end if it has no out-going edges or all its outoging edges points to dead ends. For example, consider the graph A->B->C->D. All nodes A,B,C,D are dead ends by this definition. D is a dead end because it has no outgoing edge. C is a dead end because its only out-going neighbor, D, is a dead end. B is a dead end for the same reason, so is A. <ol><li>(10 points) Find all dead ends of the dataset web-Google_10k.txt. For full score, your algorithm must run in less than 15 seconds. The output must be written to a file named deadends_10k.tsv</li> <li>(10 points) Find all dead ends of the dataset web-Google_800k.txt. For full score, your algorithm must run in less than 1 minute. The output must be written to a file named deadends_800k.tsv</li> </ol> The output format for Question 1 is single column, where each column is the id of an dead end. See here for a sample output for the toy dataset.
Question 2 (30 points): Implement the PageRank algorithm for both datasets. The taxation parameter for both dataset is β = 0.85 and the number of PageRank iterations is T = 10. <ol> <li>(15 points)Run your algorithm for web-Google_10k.txt dataset. For full score, your algorithm must run in less than 30 seconds. The output must be written to a file named PR_10k.tsv</li> <li>(15 points)Run your algorithm for web-Google.txt dataset. For full score, your algorithm must run in less than 2 minutes. The output must be written to a file named PR_800k.tsv</li> </ol> The output format for Question 2 is two-column:
Here is a sample output for the toy dataset above. </ol>
Note 1: Submit your code and output data to the Connex
Q1: How do I deal with dead ends?
Answer: I deal with deadend by recursively removing dead ends from the graph until there is no dead end. Then, I calculate the PageRank for the remaining nodes. Upon having the PageRank scores, I update the score for dead ends, by the reverse removing oder. Here I stress that the update order is reverse.
Q2: Do I initiate the PageRank score?
Answer: You should initiate the PageRank score for each page to be the same. Remember that we only run the actual PageRank after removing dead ends. Let’s say the number of pages after removing dead ends is Np, then each node should be initialized a PageRank score of 1.0/Np. It does not matter how do you initialze PageRanke score for dead ends because they are not involved in the actual PageRank calculation.
Q3: How do I know that my calculation is correct?
Answer: Run your algorithm on the sample input, make sure that the order of the pages by the PageRank scores matches with that of the sample output. There may be a slight difference in the PageRanke scores itself (because of round-off error), but the oder of the pages should be unaffected.
Also, check with the following outputs, that I take 10 pages with highest PageRank scores for each dataset:
Q4: What do I do if I get the out of memory error on 800K dataset?
Answer: It’s probably because you construct a transition matrix to do PageRank computation. This matrix takes about 5TB (not GB) of memory, so it’s is natural that you will run out of memory. The way to get around is using a adjacency list, say L, together with the algorithm in page 21 of my note. For node i, L[i] is the set of nodes that link to i. Also, you should use a degree array D, where D[i] is the out-degree of i. That is, D[i] is the number of links from i to other nodes.
Q5: How do I find dead ends efficiently?
Answer: You probably want to check this out.
Published:
Due by February 11, 2019 11:55 pm
Please note that written homework 2 is up.
Goal: In this assignment, we will experiment with three different algorithms to train a linear regression models: solving normal equations, batch gradient descent, stochastic gradient descent.
Input Format: The datasets are given in tvs (tab-separated) format. The file format is:
An example file can be found here. There are two dataset that we will work with in this assignment.
The dataset can be downloaded from here.
Output Format: output must be given in tsv format, with (D+1) columns and two rows:
The sample output for the sample dataset above can be downloaded here.
There are three questions in this assigment. The first and second question are worth 10 points each where the third question is worth 30 points, all of 50 points total.
Question 1 (10 points): Implement the algoithm that solves the normal equation to learn linear regression models. For full score, your algorithm must run in less than 1 minutes on the dataset data_100k_300.tsv, with the loss function value less than 70.
Question 2 (10 points): Implement the batch gradient descent algorithm, with T = 200 epochs, learning rate η = 0.000001 (this is 10-6). For full score, your algorithm must run in less than 5 minutes on the dataset data_10k_100.tsv with loss value less than 270,000 (this is 27x104).
Question 3 (30 points): Implement the stochastic gradient descent algorithm with: <ol> <li>T = 20 epochs, learning rate η = 0.000001 (this is 10-6) and batch size m = 1 on the dataset data_10k_100.tsv. For full score, your algorithm must run in less than 1 minutes with loss value less than 30.</li> <li>T = 12 epochs, learning rate η = 0.0000001 (this is 10-7) and batch size m = 1 on the dataset data_100k_300.tsv. For full score, your algorithm must run in less than 10 minutes with loss value less than 70.</li> </ol> Each part in question 3 is worth 15 points.
Note 1: Submit your code and output data to the Connex
Q1: Can I use libarary for computing matrix inversion in Question 1.
Answer: Yes. You are allowed Numpy in question 1. You can also use Numpy for other questions as well.
Q2: How do I initiate the weight vector for gradient descent?
Answer: I initiat the weight vector randomly where each component is drawn from [0,1] randomly using numpy.random.random_sample()
Q3: What loss function should I use?
Answer: For all questions, you should use this loss function: 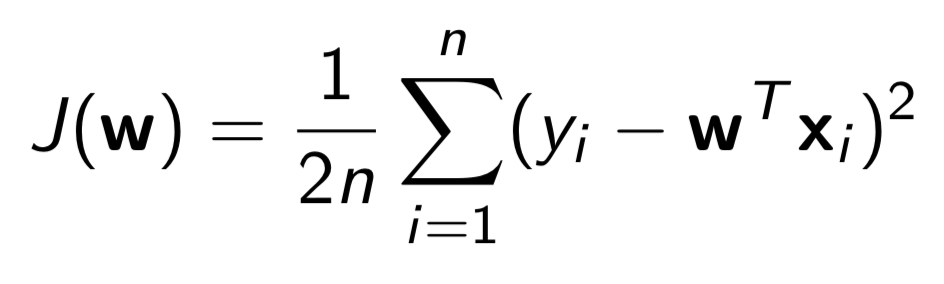
Published:
Due by Jan 28, 2019 11:55 pm
Note written homework 1 is up.
Goal: In this assignment, we will apply the locality sensitive hashing technique learned in the lecture to a question dataset. The goal is: for each question X, find a set of questions Y in the data set such that Sim(X,Y) ⩾ 0.6, where the similarity is Jaccard.
Input Format: The datasets are given in tvs (tab-separated) format. The file contains two columns: qid and question. Four datasets provided in a single zip-compressed file are:
The dataset can be downloaded from here.
Output Format: output must be given in tsv forrmat, with two columns: qid and similar-qids where qid is the qid of the queried question and similar-qids is the set of similar questions given by their qids. The format of column similar-qids is comma-separated. If a question has no similar question, then this column is empty. Below is an example of the output format:
| qid | similar-qids |
|---|---|
| 11 | |
| 13 | 145970 |
| 15 | 229098,280602,6603,204128,164826,238609,65667,139632,265843,143673,217736,38330 |
The way to interpret the above sample output is: the question of qid 11 has no similar question, the question of qid 13 has 1 similar question of qid 145970 and the question of qid 15 has 12 similar questions. You can download a sample output tsv file here. The name of the output file must be question_sim_[*].tsv where [*] is replaced by the size of the dataset. For example, the output of the 4k question data set must be question_sim_4k.tsv.
There are two questions in this assigment. The first question is worth 15 points and the second question is worth 35 points, all of 50 points total.
Question 1 (15 points): Implement the native algorithm that, for each question, loops through the database, computes the Jaccard similarity and output questions of similarity at least 0.6. For full score, your algorithm must run in less than 3 minutes on the dataset question_4k.tsv.
Question 2 (35 points): Implement the locality sensitive hashing algorithm we learned in the class, with x = 0.6, s = 14 and r = 6, where s is the number of hash tables (we use b instead in the lecture slide) and r is the size of the minhash signature. For full score, your algorithm must run in less than 10 minutes on the dataset question_150k.tsv.
Note 1: As you may understand from the lecture, it could be that two non-similar questions are mapped to the same location in the locality sensitive data structure. This is called false positive. You must remove all false positives before writing to the output file.
Note 2: Submit your code and output data to the Connex
Q1: Will 50k and 290k question datasets be graded?
Answer: No. They are provided for learning purposes.
Q2: How can we generate a random number in Python3?
Answer: Here is an example code that I use for generating a random 64-bit integer in my implementation.
Q3: What kind of hash function do you recommend for computing the minHash signature?
Answer: In my implementation, I use the linear hash function h(x) = (a*x +b) mod p, where a,b are two random 64-bits integers and p is a 64-bit prime integer. I set p = 15373875993579943603 for all hash functions.
Q4: How can I map a string (and a word specifically for this homework) to an integer so that I can feed it to the linear hash function in Q3.
Answer: I recommend the FNV hash function. You can download and install following the instruction in here. However, I use this library in a slightly different way. Here are steps: I download the libarary, look for the file name “init.py” in the downloaded package, rename it to “fnv.py”, put to the source code folder and import to my code. Here is an example of how to import it. You may notice that there are three diffent hash functions in the example. I use this function hash(data, bits=64) in my implementation.
Q5: If I don’t use python, where can I find a version of the FNV function implementation in other languages?
Answer: You can visit this site. It might have what you want.
Q6: Do you apply any advanced processing technique to nomarlize the datasets?
Answer: I don’t. I want to keep the implementation as simple as possible for learning purpose. I do use question.strip() to remove possible white-space characters ended at each question. Then, I just use split function of Python3 question.split() to break a question into words. You may notice that in this implementation, “what” and “What” would be regarded as different words because I do not handle capitalization. You are welcome to use any technique that can help you improve the correctness of your algorithm, but keep in mind the running time constraint.
Q7: If the outputs of my implementation and another group’s implementation are different, is this a problem?
Answer: No. Because the nature of randomness in locality sensitive hashing, I expect differences in the output. The assignment will mainly be graded based on: speed and your understanding of the algorithm reflected in your code. And don’t forget the dicussion policy that I specified in class.
Short description of portfolio item number 1
Short description of portfolio item number 2
Published in , 2009
(Publications in Theoretical Computer Science are alphabetically ordered.)
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2). http://academicpages.github.io/files/paper2.pdf
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3). http://academicpages.github.io/files/paper3.pdf
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.